Building a Team Brain That Updates Itself
When a team starts building a brand-new product, the most valuable thing it owns isn't in the product yet. It's scattered across customer calls, Slack threads, WhatsApp arguments at midnight, hallway conversations, and half-finished decks. Sa'ar Arbel, who leads an engineering group at monday.com, calls this "shadow data" — and on a recent Startup for Startup episode he described how his team turned that mess into a single, self-updating "team brain" for monday's new product, Harmony.
I found the architecture genuinely clever, and it lines up with a pattern that's been making the rounds lately. This post is my attempt to unpack the idea, with interactive diagrams you can poke at, of why a living wiki beats classic retrieval, what the brain actually looks like, and how it stays current on its own.
From RAG to a living wiki
The starting point is a question everyone building with LLMs runs into: how do you let a model answer questions over a big, messy, ever-growing pile of text?
The default answer for the last few years has been RAG (retrieval-augmented generation). You chop your documents into chunks, embed each chunk as a vector, and stash them in a vector database. When a question comes in, you embed it too, pull the nearest chunks, and let the model stitch an answer together.
It works — but it has no memory. As Sa'ar puts it: it's like sending a librarian to find an answer. They scour every shelf, bring something back, and then forget everything. Ask the same question tomorrow and they search the entire library again, from scratch. Nothing accumulates.
The reframing — which traces back to Andrej Karpathy's "LLM wiki" idea — is to make the knowledge persistent. Instead of re-deriving answers on every query, you have the model compile the raw material into a structured wiki of linked pages once, and then keep it current. Answers that turn out to be useful get written back into the wiki, so the knowledge compounds instead of evaporating.
Watch the same question get asked over and over on both sides:
On the left, RAG re-scans the full corpus of raw chunks on every ask and keeps nothing — the "work per ask" meter pins to full every single time. On the right, the living wiki writes the answer into a page on the first ask (it turns green and stays); every ask after that is just a lookup, and the work meter barely moves. The plain-text wiki also has almost no failure modes: no running service, and it version-controls cleanly in Git.
A concrete example from the episode: a PM was wrestling with pricing. He opened the brain, worked through it, pulled in some competitor research, and distilled a table of every competitor, their pricing, and where Harmony's advantage lay. Then he saved that table back into the wiki. The next morning, when someone asked "what are competitors A and C charging?", the brain already knew — no trip to the open internet required.
What the brain actually looks like
So what is the wiki, structurally? The team modeled it the way you'd model a mind: a set of folders and files — concepts (the ideas that keep coming up in go-to-market and engineering), entities (companies and people, by role), decisions, and action items — all cross-linked into a graph, exactly like Wikipedia. You land on one page, see a link to a related concept, and follow it.
Each node is a wiki page; each edge is a cross-link the model wrote between two pages:
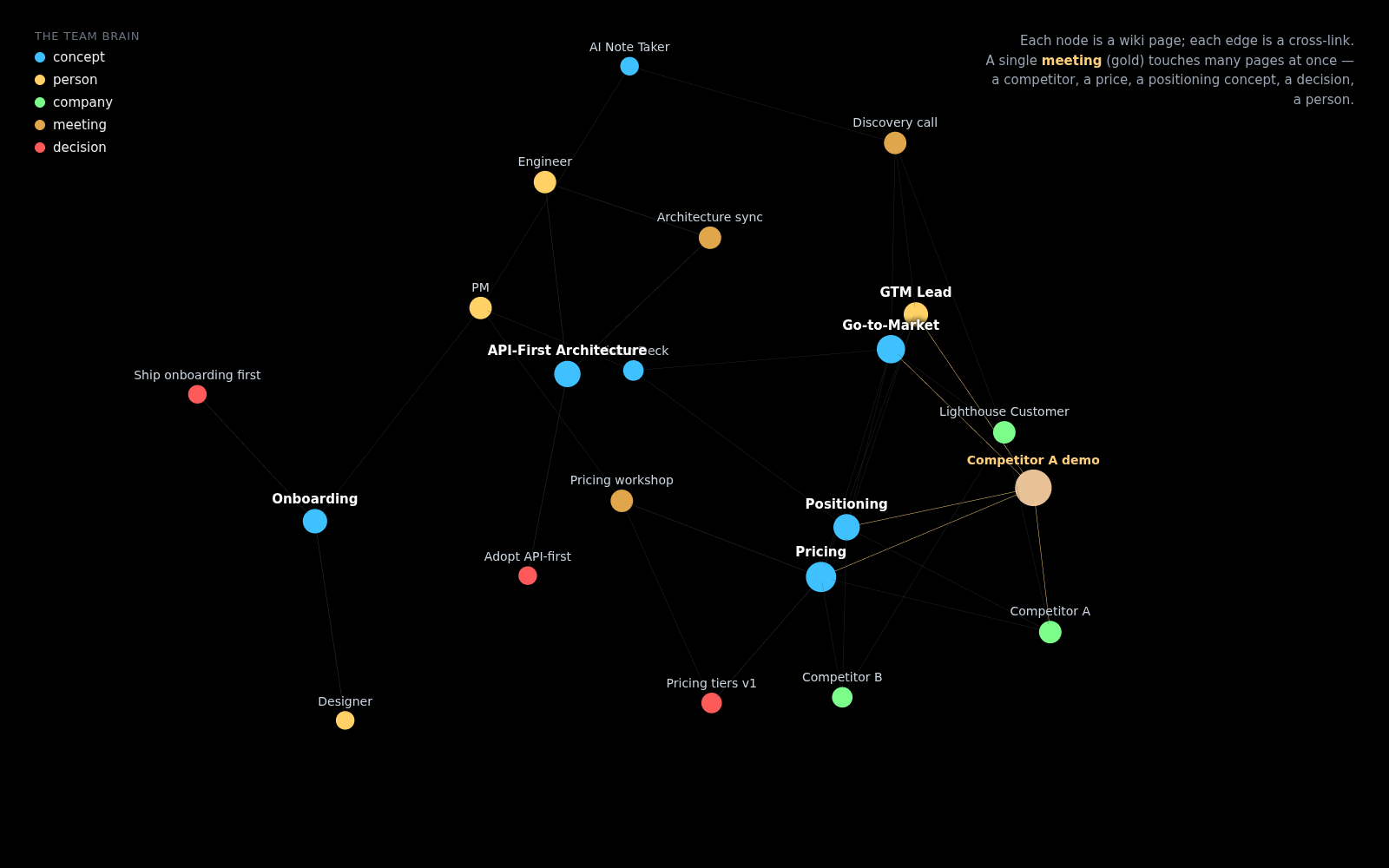
Open the page for a concept like "API-First Architecture" and you can see which meetings raised it, who brought it up, how the team defined it, and whether competitors do the same thing. The gold node is a single meeting — "Competitor A demo" — and the gold edges are the cross-links it wrote in one pass: to a competitor, a pricing page, a positioning concept, the go-to-market page, and a person.
That gold fan-out is the crux of why it's a graph and not a folder of notes. A single discovery call isn't about one thing — it touches a competitor, a feature, a pricing question, and an architectural constraint all at once, so ingesting it updates many pages simultaneously.
Keeping it alive: everyone is a node
A wiki you have to update by hand dies in a week. The hard part is making it stay current on its own, across a whole team.
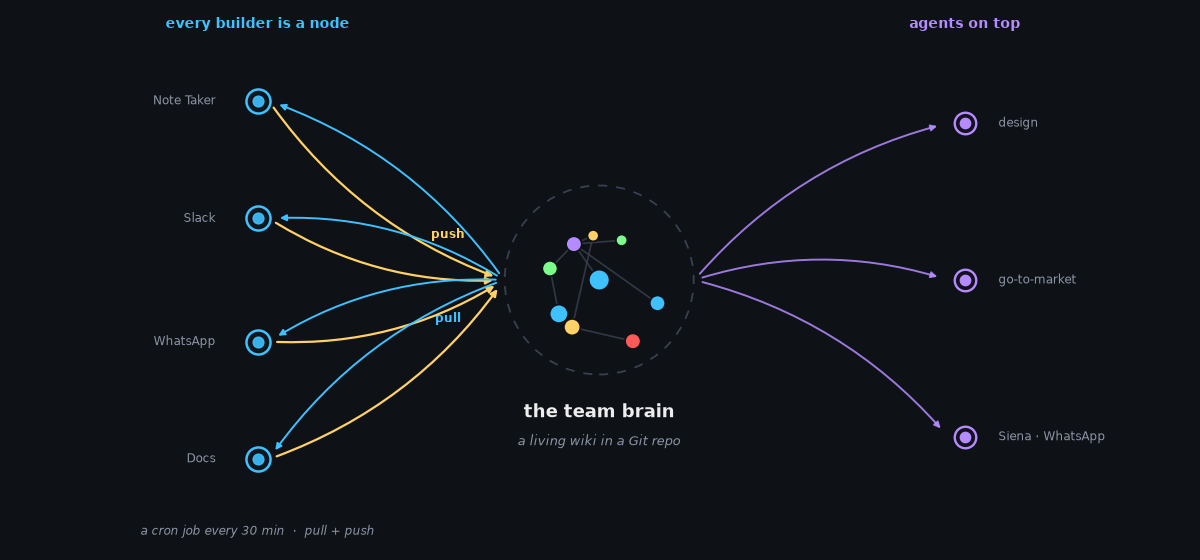
The first version was a single workflow on Sa'ar's machine: after each meeting, the AI Note Taker hands over a transcript, an agent connects to Slack, WhatsApp, and Docs through their MCP servers, and folds the new information into three little files in a Git repo. Simple, and it worked — but it only captured his context, and standing up 4–5 workflows per person across 20 people (100 workflows) doesn't scale.
The fix: make every person a node in the same network. Each builder runs a scheduled job — a cron every half hour — that pulls the shared memory from Git, fetches new context from their sources, computes what to add, and pushes it back. Everyone's meetings flow into one shared brain, and everyone stays synced without a single alignment meeting.
The brain sits in the middle (it's just a Git repo). Each builder pulls data from their own sources — Note Taker, Slack, WhatsApp, Docs — and their cron job streams context in (push, gold) and out (pull, cyan), so the memory is always live. The outer ring is the next layer: autonomous agents, including a WhatsApp assistant the team named Siena, that read from the same brain (violet) and act on top of it.
On top of the repo, the team exposed the brain in the ways humans actually work: a Wikipedia-style website you can read like a morning newspaper, the editors in Cursor and Claude that engineers already live in, and Siena, a WhatsApp agent wired to the same memory. Out sick, on reserve duty, or on holiday? Message Siena and catch up on everything that happened, 24/7.
What it actually changes
The payoff is that the brain quietly accumulates more cross-context than any single person on the team. A few moments from the episode that stuck with me:
- A vision deck in hours, not weeks. Putting together a vision presentation for the CEO — market research, competitive analysis, design — normally eats weeks. Grounded in everything the brain already knew from past conversations, the PMs closed it in a few hours.
- Marketing with no marketer. With no dedicated marketing hire, they wired the brain into Claude and asked it to generate Google Ads messaging. The campaigns ran well and brought in solid leads — because the brain had more context on the product and audience than any individual did.
- "Read the Note Taker first." The cultural norm flipped. People stopped repeating themselves; if you missed a conversation, you ask the brain, not a colleague.
The uncomfortable part
It isn't all clean. Two honest caveats from the episode worth repeating if you try this:
Radical transparency is a real mindset shift. In this architecture, everything recorded or written is accessible to everyone — there's no asymmetry between a PM, an engineer, and a designer. That's powerful, but it means your "private" Slack channel effectively isn't anymore. The team came to see this as a feature, but it's a genuine change in how people work. Want an off-the-record chat? Turn the Note Taker off.
The guardrails are earned, not free. Early on the system happily synced private 1:1 conversations — sometimes with personal content — straight into the shared repo. More than once they had to wipe the Git repo and rebuild it clean, then tighten the skills so it wouldn't happen again. A self-updating memory needs guardrails about what it's allowed to remember, and you'll discover the missing ones the hard way.
Where it's going: agents on top of the brain
The direction is the part that feels like the actual bet. Once the context lives in one place and is exposed cleanly over an API, the brain becomes a substrate for autonomous agents — one per discipline (design, product, go-to-market, R&D), each built on top of the brain. The marketing example is heading toward fully autonomous: the agent decides budget and messaging per channel and executes, with humans barely in the loop.
Sa'ar's framing, which I think is right: agents themselves are now a largely solved problem — they have tools, a runtime, files. The hard, valuable part is feeding them the right context. A living team brain is exactly that context layer.
If you want to build one
The advice from someone who actually shipped it is refreshingly anti-heroic:
- Start simple and local. Connect a couple of MCP servers (Note Taker, Slack, Docs), ask Claude to sketch a wiki structure for your org — borrowing from Karpathy's repo as a reference — and just live with it for a while.
- Don't over-engineer it. The temptation is to make everything automated and CI/CD-driven from day one. Resist it. Scaling is fun for engineers, but it's not the point here. People build a car before they can ride a bike.
- Optimize for a memory that's alive, not pretty. Prove the value with something basic and manual, watch where it actually helps, then grow it.
The pieces here aren't new — persistent knowledge bases, knowledge graphs, scheduled jobs, MCP connectors. What's new is how cheap it's become to wire them together with an LLM at the center, and the realization that the real objective isn't a clever retrieval algorithm. It's a shared memory that's alive: one that every conversation updates, and that everyone — and increasingly every agent — can build on.