How Eon Turns Cloud Backups Into an AI-Queryable Data Lake
I recently listened to a Geekonomy episode with Dr. Assaf Natanzon, Chief Architect at Eon, and it reframed something I thought I understood. Eon started life as a cloud-backup company. Somewhere along the way they realized that the artifact a backup product already produces - a normalized, queryable copy of every piece of data in the organization - is exactly the thing AI has been starving for. Assaf called it the new Library of Alexandria: one place that holds everything the company knows, finally in a form a machine can read.
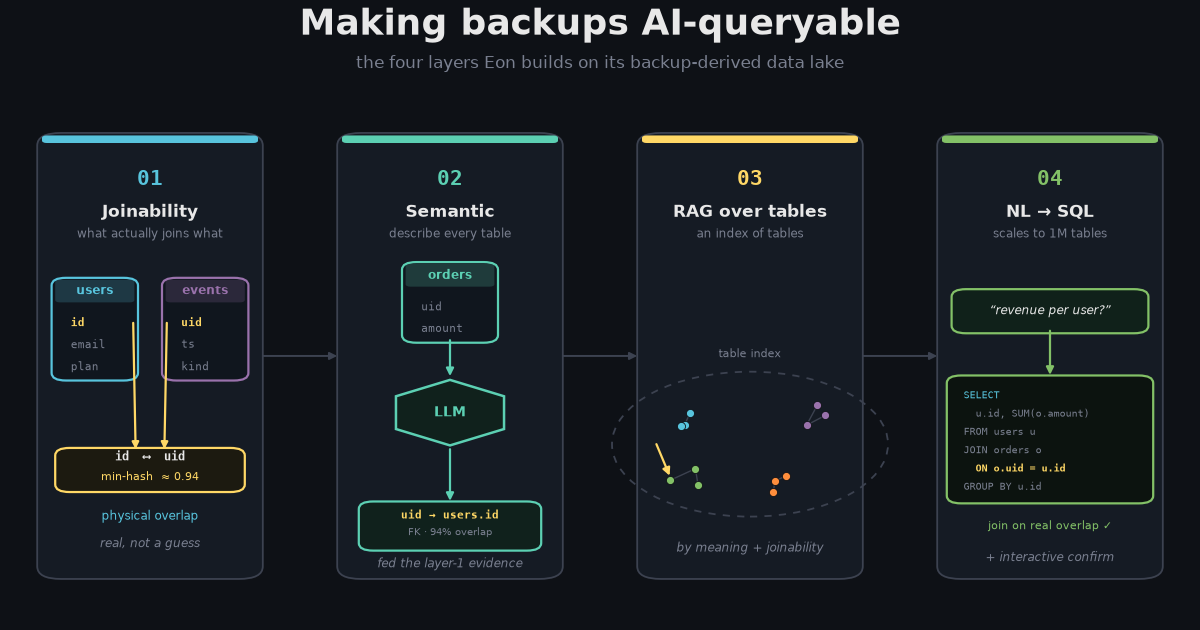
What I loved, much like the monday.com episode I wrote up earlier, is that it isn't abstract hype. It's a stack of concrete engineering decisions, each one solving a failure mode the layer above it couldn't. This post walks through that stack: first how the backup quietly becomes a data lake, and then the four AI layers Eon builds on top to make it answerable in natural language.
The accidental data lake
Before any AI enters the picture, Eon does something clever with the backup itself.
- Agentless discovery. You give Eon an IAM role, nothing to install. It enumerates every resource in your cloud accounts and auto-classifies what's inside each one - which databases, which engines, what's production, what contains PII.
- Snapshot → scan → re-encode. Cloud-native snapshots are opaque blobs; you can restore them but you can't query them. Eon rewrites each one into an open, queryable format sitting in your own S3.
- Tabular, in the open. Databases get extracted to Parquet and exposed as Apache Iceberg tables - complete with time-travel snapshots, so "what did this table look like last Tuesday" is a first-class question.
- Zero-ETL, as a side effect. Because every backed-up source lands in the same Iceberg lake, you get a unified, multi-cloud, multi-SaaS data lake for free. Nobody had to build and babysit a pipeline; it falls out of doing backup correctly.
That last point is the whole trick. The backup is the data lake. Everything below is about making that lake answerable.
The four layers that make it answerable
Here's a ~60-second walkthrough of the four AI layers, which I'll unpack one at a time below.
1. Joinability detection - what actually joins what
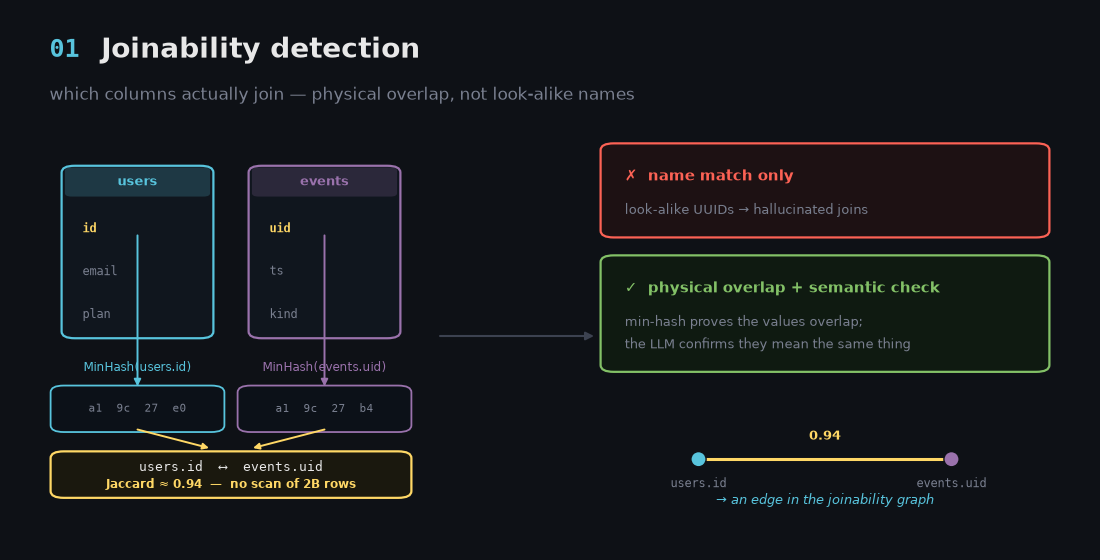
The first hard problem: the same logical entity shows up across many sources under different column names, sometimes with no schema at all (think raw Mongo JSON). Before you can answer a cross-source question, you have to know which columns are actually joinable.
Both naive approaches fail. Ask an LLM to match column names and it will happily join two look-alike id columns that have nothing to do with each other. Brute-force the intersection across billions of rows and you go broke.
Eon combines a cheap physical check with a semantic one:
- Physical overlap via min-hash. Two columns of a billion values each can be tested for, say, 10% overlap without scanning two billion values - the min-hash sketch estimates the Jaccard similarity from a tiny fingerprint.
- Semantic confirmation on top. A 1..N counter in one table will "overlap" 100% with an unrelated 1..N counter in another. So an LLM looks at the column names, sampled values, and surrounding columns to confirm the meaning matches, not just the numbers.
The output is a graph: which columns in which tables genuinely join, with confidence scores. Physical overlap, not a guess.
2. Semantic analysis - describing every table
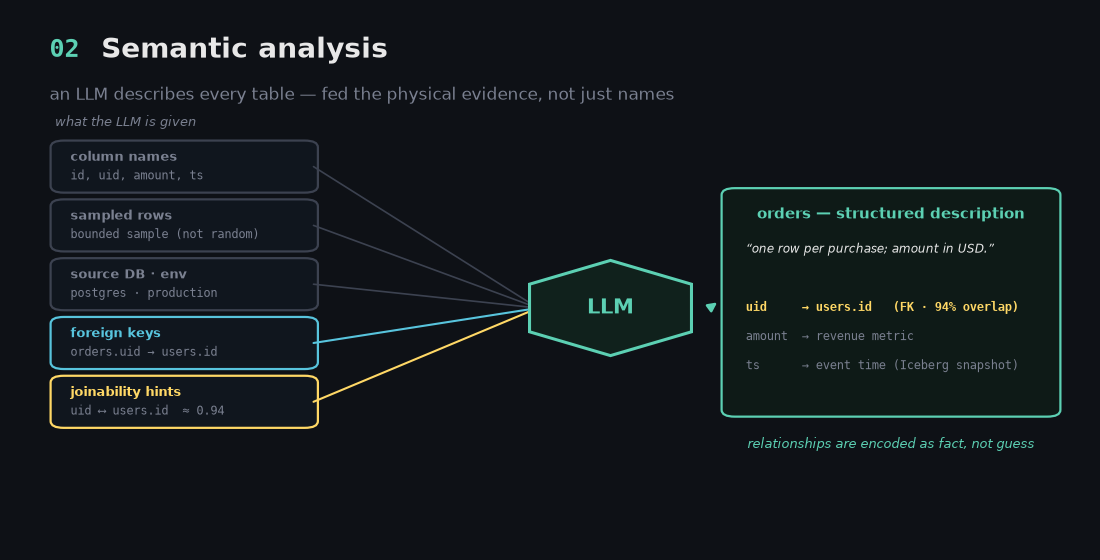
This runs at ingest, once per table, and produces the metadata everything else stands on. For each table the LLM is fed the column names, a bounded sample of rows, the source DB and environment, any detected foreign keys - and crucially, the joinability candidates from layer 1.
It returns a structured description: what each column means, what the table represents, how it relates to its neighbors. It works even for schemaless Mongo collections, where the LLM does schema inference from sampled JSON.
The key insight is the contrast with the obvious thing. An LLM wired straight to a database sees only the semantic signal - names and values - and has to guess at relationships. Eon hands the LLM the physical-overlap evidence too, so the descriptions encode relationships that are real (uid → users.id, foreign key, 94% overlap) rather than plausible.
3. RAG over tables - an index of tables, not documents
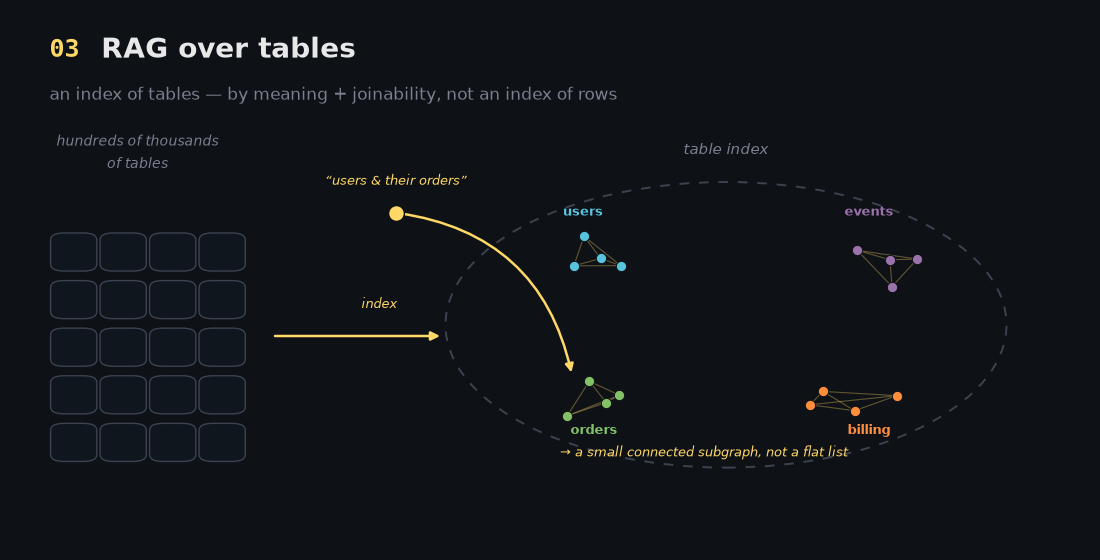
This is the layer I had to recalibrate. The RAG here isn't over your rows or your documents - it's an index over table metadata and relationships. Each table gets an index entry containing its name and origin, the per-column descriptions from layer 2, sample values, contextual metadata, and the cluster of tables it joins to from layer 1.
Two things sit on top:
- Search - "what tables do we have about X?" returns the relevant cluster.
- Clustering - tables that share joinable columns are grouped, so a question about "users and their orders" resolves to a small connected subgraph instead of a flat list of a million tables.
In other words, each cluster is a subgraph of the joinability graph, described in the language of layer 2. That's what makes the next layer tractable.
4. NL2SQL - that survives a million tables
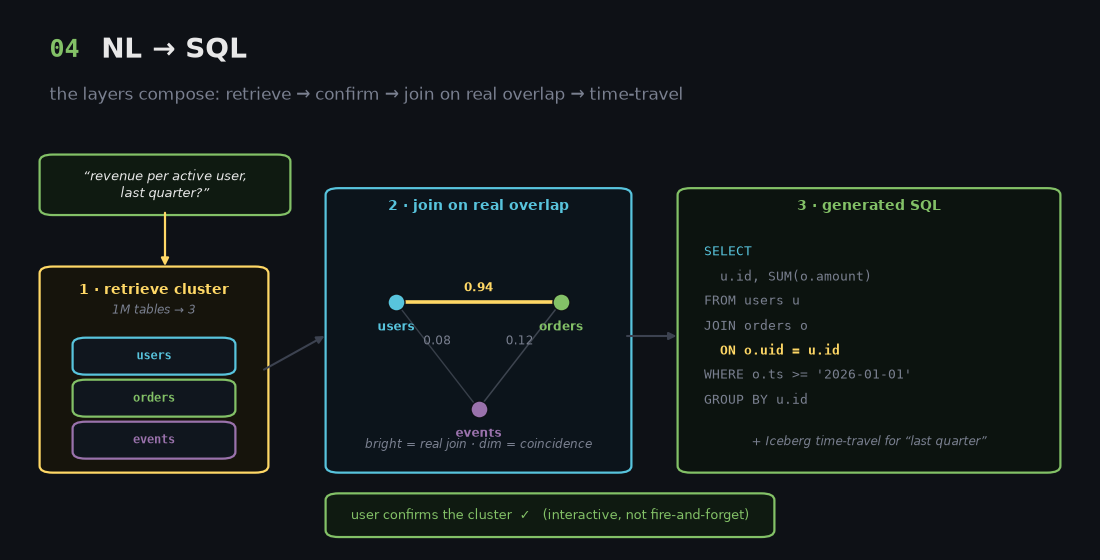
Off-the-shelf natural-language-to-SQL handles maybe a hundred tables and then collapses. Eon's customers have hundreds of thousands. The four layers compose to make that scale work:
- Retrieve the relevant cluster. The RAG layer turns a million-table problem into a ten-table problem.
- Confirm interactively. The UI shows the proposed cluster and lets the user correct it before any SQL is written. Not fire-and-forget.
- Generate SQL with joinability as ground truth. Instead of guessing
ON a.user_id = b.user_id, the LLM is told "these two columns physically overlap 94%, join on these." - Pick the right snapshot. Iceberg time-travel lets it answer "today's state" or "the trend over the last year" by choosing the correct snapshot.
Each layer covers a failure mode the others can't: RAG narrows the search space, joinability makes the joins real, the semantic descriptions let the model write correct SQL, and the interactive step catches whatever's still wrong.
My takeaway
The thing that stuck with me is that the moat here isn't the LLM. Anyone can point a model at a database. Eon's advantage is the physical evidence it feeds the model at every step - min-hash overlaps, real foreign keys, Iceberg snapshots - so the AI is reasoning over ground truth instead of guessing from column names. The backup was never just insurance; it turns out to be the cleanest, most complete substrate for AI a company already owns.
Eon has since shipped this as a natural-language AI agent over backup data and is pitching the backup-as-analytics-lake idea directly to data teams. If you're building "AI for data" inside your own company, the lesson generalizes past backups: spend your effort on the layers that give the model real evidence, and the LLM part gets a lot easier.
The animation above was made with Manim; the scene source and a writeup of the four layers live in research/eon-layers/.