Training a Hebrew LLM: Behind the Scenes of Hebatron
There's a Hebrew language model called Hebatron that, in a single week, racked up 30,000 downloads and four community quantizations. For an open model that isn't in English, that's a lot. I listened to the ExplAInable episode where the team that built it walked through how it was made — and it turned out to be one of the most honest accounts of actually training a model I've heard: the dead ends, the 200 failed runs, the one-line change that finally worked. This post is my attempt to lay that story out with the diagrams I wish the audio had.
Hebatron is a continued pre-train + fine-tune of NVIDIA's Nemotron — not a from-scratch model. That's how almost everyone outside the few giant labs builds these days: you take a strong open base and teach it your language or domain. The interesting part is everything that goes wrong between "take a base model" and "ship a model people actually download." It was built by the team at PwC NEXT together with Israel's National AI Program, on infrastructure donated by AWS.
Why Hebrew breaks the usual recipe
The first problem is the language itself. Hebrew is what the literature calls a morphologically rich language: the grammatical role that English spreads across separate little words — and, to, the — gets glued directly onto the root. One Hebrew word can carry an article, a preposition, and a conjunction all at once.
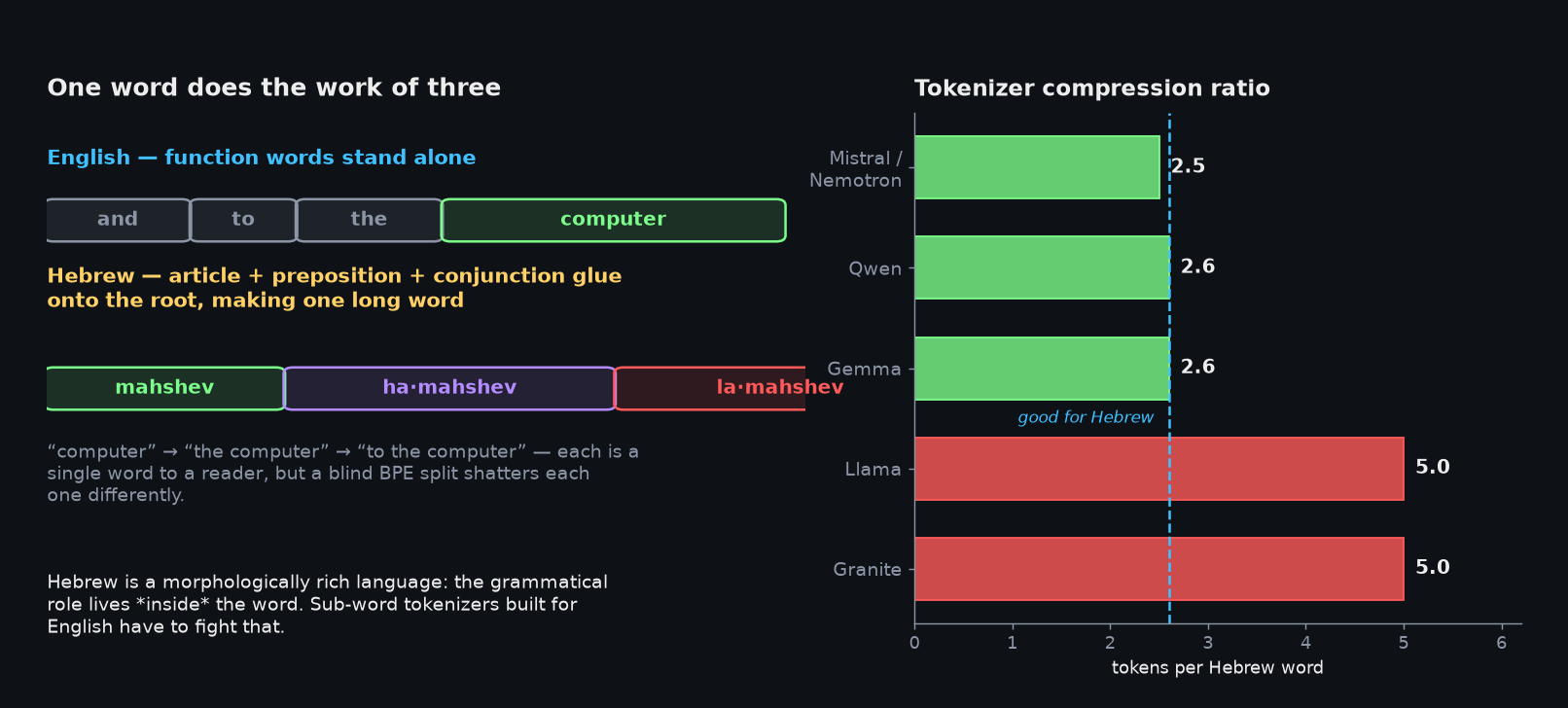
Standard tokenizers are trained with BPE, which finds frequent sub-word chunks statistically. That works beautifully for English, where function words already stand alone. In Hebrew, a blind statistical split shatters each inflected form differently, and the practical consequence is captured by one number: the tokenizer's compression ratio — how many tokens it takes to write the average Hebrew word. The team's punchline is that this single number almost tells you in advance how hard the model will be to train. A tokenizer that needs ~5 tokens per word (Llama, IBM's Granite) means five times more next-token predictions per word and a context window that fills up twice as fast. One around 2.5 (Mistral, Qwen, Gemma, and Nemotron — which reuses Mistral's tokenizer) is in a completely different regime. They explored Hebrew-specific tokenization, but in the end went with the standard approach everyone else uses — the ecosystem has voted, and fighting it wasn't worth it.
Picking a base model: learnable beats "strongest on the board"
With the tokenizer constraint in hand, choosing a base model becomes a multi-way trade-off. License first — it has to allow commercial use and be genuinely open, ideally including the base model, not just an instruction-tuned checkpoint. Then the tokenizer. Then a subtler property the team kept bumping into:
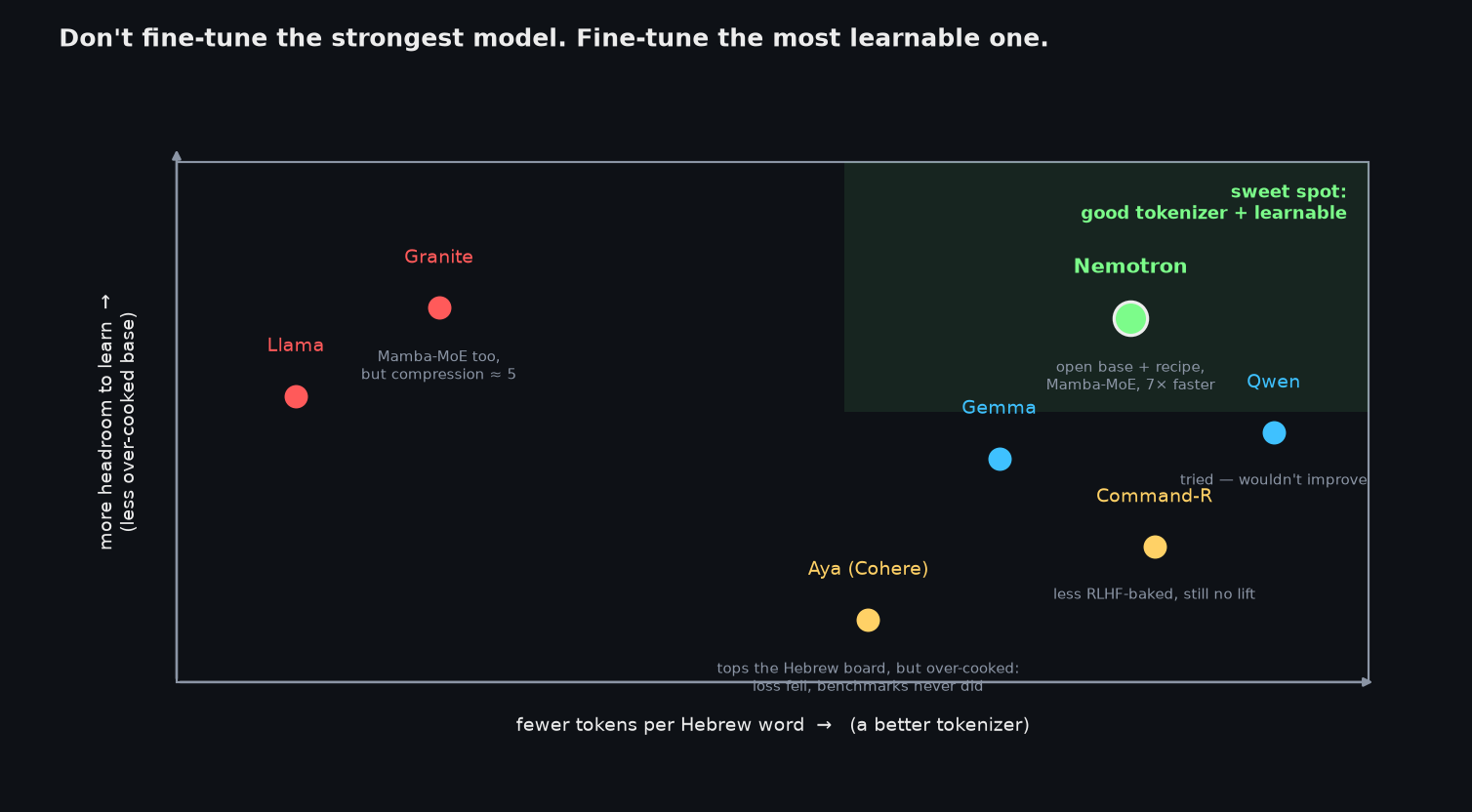
The model the national program initially recommended was Aya, from Cohere — it topped the Hebrew leaderboards. But Aya ships only as a heavily instruction-tuned model, built with iterative instruction-tuning, model-merging ("merge of experts" — averaging the weights of copies trained on different domains), and a stack of other tricks. The result is brilliant out of the box and almost impossible to fine-tune further. The team tried, repeatedly: the training loss would drop, but the Hebrew benchmarks never climbed back above where Aya already was. Command-R (less aggressively post-trained) didn't budge either. As one of them put it, it's "mumbo-jumbo that works" — and precisely because every layer has been massaged, there's no clean handle left to grab.
That's the lesson worth stealing: when you plan to fine-tune, don't reach for the strongest model on the benchmark — reach for the most learnable one. A slightly-weaker base with headroom beats a maxed-out one that has stopped moving. Nemotron won because it sat in the sweet spot: a fully open base with its training recipe published, a 2.5 tokenizer, and — the architectural bonus — a hybrid Mamba + Mixture-of-Experts design that ran about 7× faster than the alternatives they'd benchmarked. (IBM's Granite is the same Mamba-MoE family, but its ~5 tokenizer ruled it out.)
Mixing the data: it's not where it's from, it's what it is
Compute was roughly fixed, the architecture was chosen — which left data as the biggest lever. Most data-mixing methods weight your corpus by its source: national library vs. web crawl. The team's insight was that source is the wrong axis. A library holds both poetry and accounting textbooks; so does the open web. What the model cares about is the content type, not the shelf it came from.
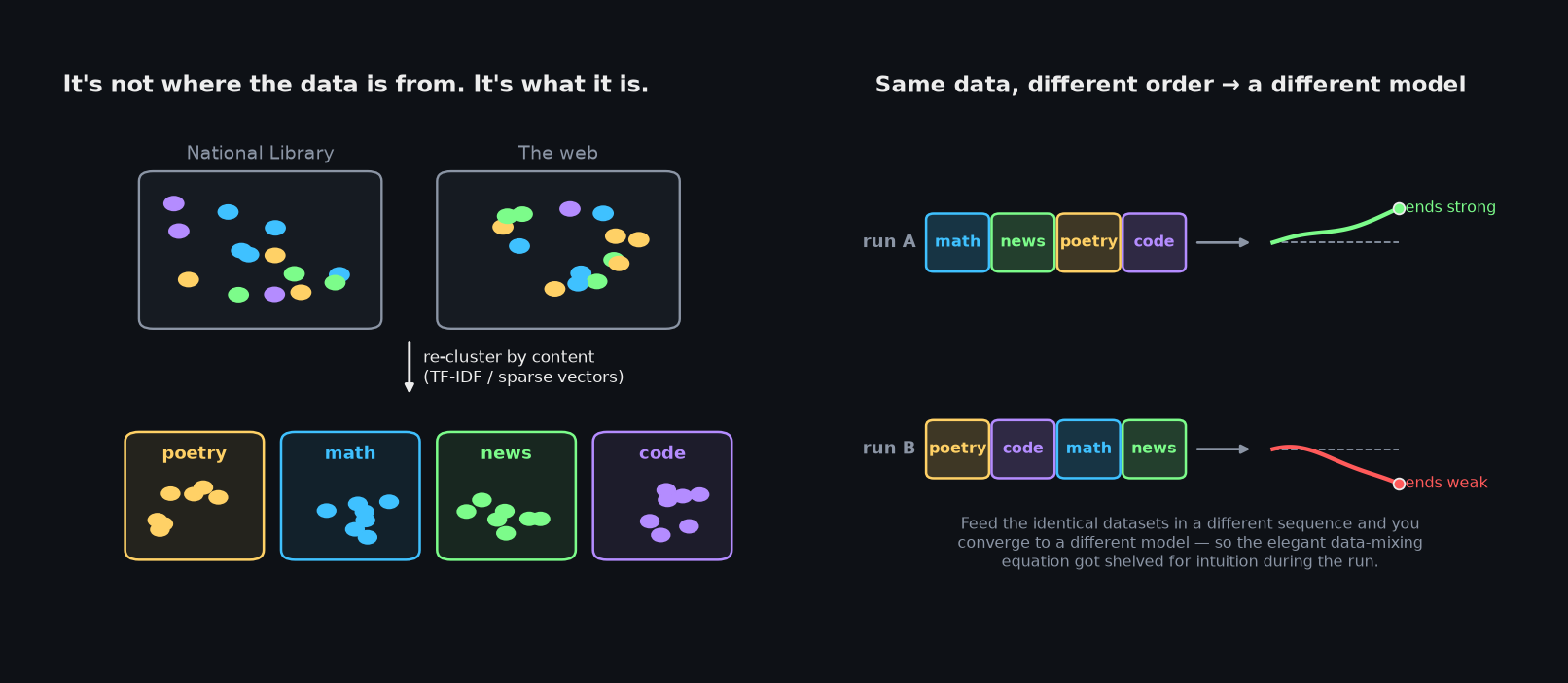
So they ran TF-IDF and sparse vectors over the corpus, re-clustered it by content, sampled the extremes (the 2σ tails), and even trained small probe models to predict how much each kind of data would help. Inspired by a paper that frames the data mix as a portfolio-optimization problem — diversify across "assets" so every relevant domain is covered — they derived an elegant equation for the optimal mixture.
And then they didn't use it. Two reasons. First, they kept swapping the base model, so any plan went stale. But the deeper reason is the right panel above: they found that it's not just the quality of the data, it's the order you feed it in. Some of the final gains came from training on the same datasets in a different sequence. Once order matters, the search space is the number of permutations of your datasets — 20 datasets is ~10¹⁸ orderings — and no equation or grid search survives that. The honest takeaway, which recurs through the whole project: we understand far less about why training works than the tidy papers suggest, and a lot of it still comes down to intuition during the run. (This line of data-mixing research is real and worth reading — see DoReMi — it just doesn't yet give you a recipe you can follow blindly.)
The crisis: loss goes down, benchmarks go down
Here's the part that makes you respect how hard this is. Across roughly 200 training runs — different regularization, different Hebrew/English balance, different data — the same maddening pattern kept showing up: training loss fell, validation loss fell, and the benchmarks came out worse than the model they started with. Every textbook signal said "it's learning." It wasn't.
The only correlation they ever found was a negative one: when the loss rose early in a run, that run was doomed. So loss became useful as a way to kill a bad run early — but never as evidence that a benchmark would improve. That disconnect between loss and capability is the single most important thing in this whole story, and it sent them looking for what was actually changing inside the model.
Why a Mixture-of-Experts wastes itself on a new language
One culprit was the architecture they'd chosen. In a Mixture-of-Experts model, a router sends each token to a few of many "expert" sub-networks. They measured the routing entropy — how evenly the experts get used — and found it behaves very differently in Hebrew than in English.
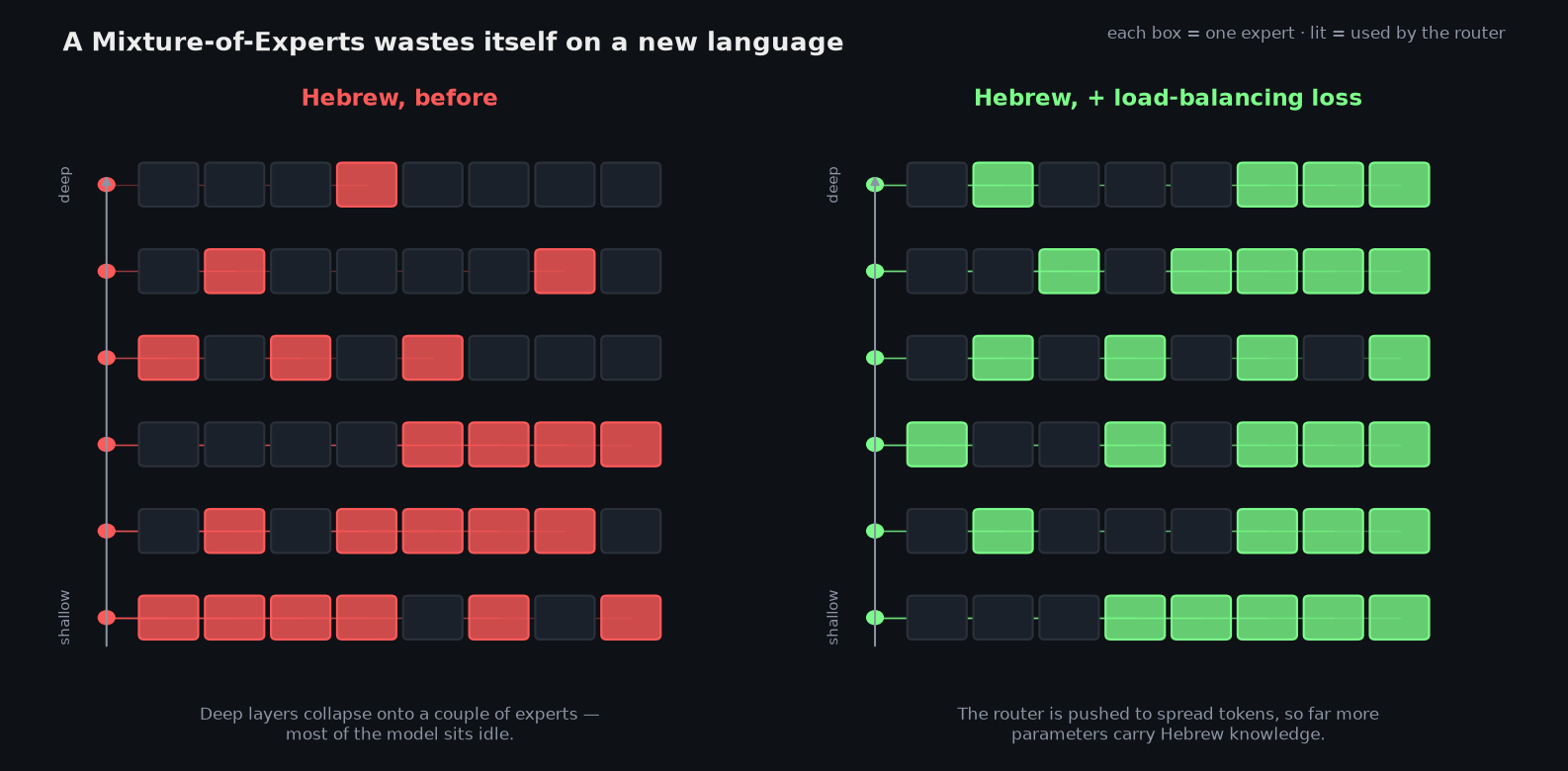
Because Nemotron had seen little Hebrew, the routing collapsed toward the deep layers: on Hebrew text, the model leaned on just a handful of experts in its final layers and left the rest idle. A huge fraction of the model's capacity was sitting unused exactly where it mattered. The fix is a standard MoE tool — an auxiliary load-balancing loss that penalizes the router for always picking the same experts, forcing it to spread tokens more aggressively. That costs a little reasoning quality at first, but it brings far more parameters into play, so the model can absorb more Hebrew knowledge.
It helped, and a retrospective analysis confirmed it was real — the experts only re-balanced around step 1,300, and the model's original capabilities only came back around step 2,600. But it still didn't explain why benchmarks stayed flat even after 4,000 steps. Something else was wrong.
The fix nobody expected: make the batch bigger
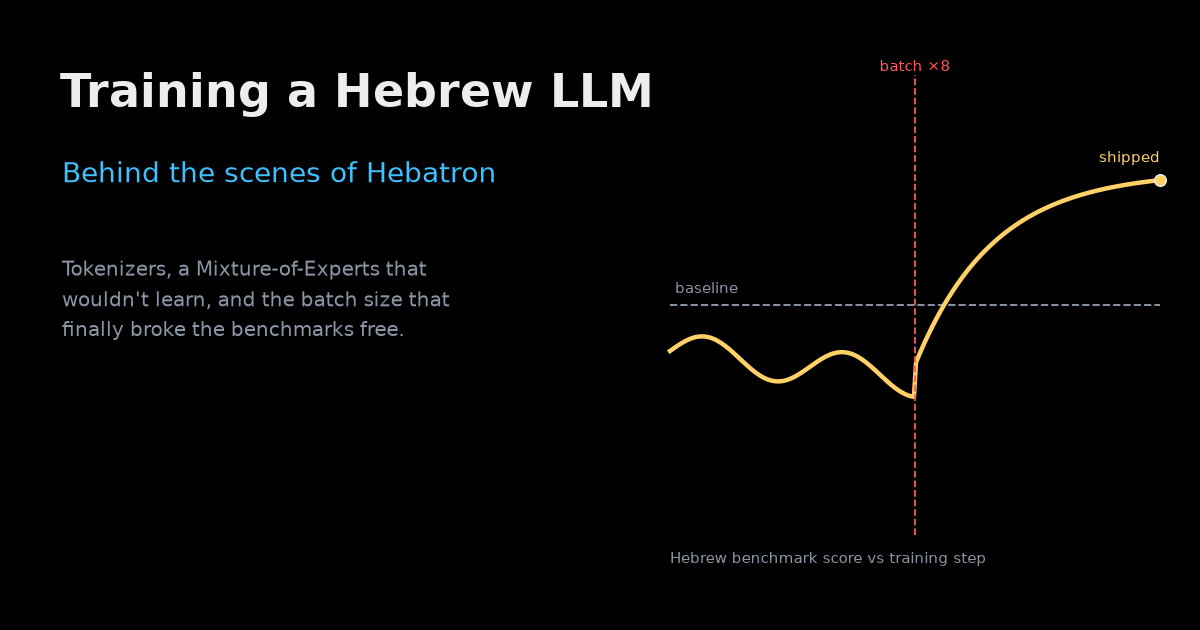
The breakthrough came from a paper an advisor flagged on a Friday: An Empirical Model of Large-Batch Training. Its argument is simple: there's a gradient noise scale — a critical batch size — and where you sit relative to it determines whether training is efficient. The team's plan was ~250B tokens; the rule of thumb says you want that spread over roughly 20k–100k optimizer steps. They were running a global batch of about 2M tokens (an 8K context × 256), which put them at ~125k steps — too many small, noisy steps:
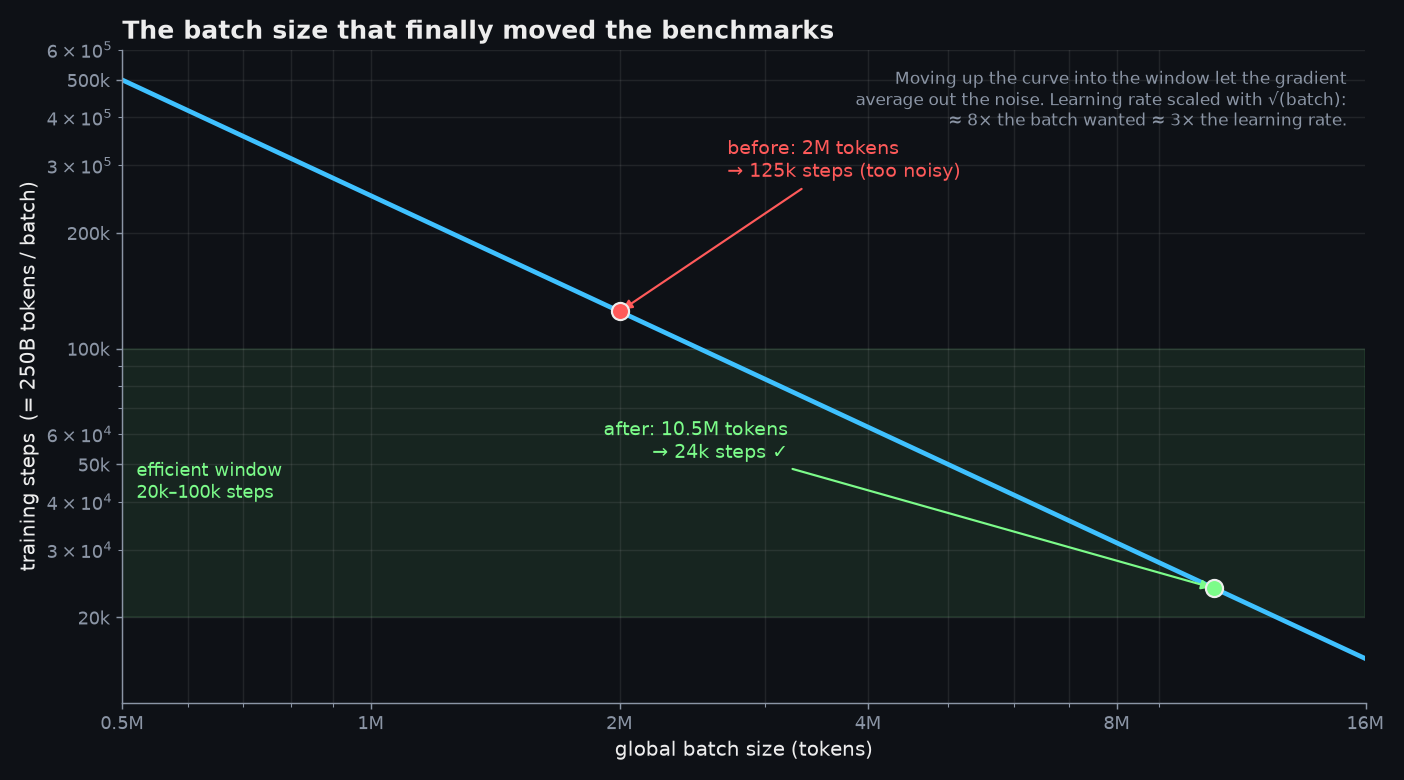
So they scaled the global batch up — eventually to 10.5M tokens — landing back in the efficient window where the gradient averages out the noise. A second paper, Don't Decay the Learning Rate, Increase the Batch Size, told them how to keep the dynamics intact: noise shrinks with the square root of the batch, so the learning rate should grow the same way — an 8× batch wants roughly a 3× learning rate. They made the change, went to sleep, and... nothing. The benchmarks sat still. The run was only still alive the next morning because someone forgot to shut the machine down — and that's when the benchmarks finally jumped, +12 over baseline. That's the model that shipped.
The meta-point, again: nobody — not even the person who recommended the paper — expected the effect to be that large. An enormous amount of training is hidden in hyperparameters you'd never guess mattered, and sometimes the only thing separating a failed run from a shipped model is the stubbornness to leave it running one more day.
Benchmarks vs. the Arena
Which version do you actually ship? The team had a whole battery of benchmarks — psychometric exams, math, translated-and-localized versions of standard reasoning tests — and they often disagreed with each other (a model can gain on trivia while losing on reasoning, which averages to "no change" while the model is quietly becoming a different thing). They also disagreed with the Arena, where real users compare outputs head-to-head. In the end they shipped a version that scored 3 points lower on their own benchmarks because it was preferred by users in the Arena — on the bet that the public uses a model, it doesn't run benchmarks on it.
SFT: the bookkeeping is the hard part
After continued pre-training comes supervised fine-tuning, and a chunk of the work there is unglamorous plumbing. Two pieces stood out.

Loss masking: in pre-training you compute loss on every token. In SFT you only want loss on the assistant's response, not the user's prompt — so you mask the prompt tokens out. Packing: a 4K answer in an 8K context window wastes half the GPU, so you pack several examples end-to-end and avoid padding. Each is simple alone; combining them — packing and masking the loss to only the response spans within each packed window — is fiddly, and the framework they used (NVIDIA's Megatron-Bridge) didn't handle it for SFT out of the box. So the team had to build the packer themselves. (Choosing Nemotron paid off again here: its full instruction-tuning recipe was published, so they weren't reverse-engineering the SFT stage.)
The fourth pillar: infrastructure
It's easy to talk about data, algorithms, and benchmarks and forget that none of it runs without GPUs — and that the infrastructure is its own deep specialty. Hebatron trained on AWS HyperPod: clusters of 8×8 = 64 H200 GPUs wired together with AWS's EFA interconnect. That networking took real effort to learn, but once it worked, scaling was linear — add a second cluster, halve the time.
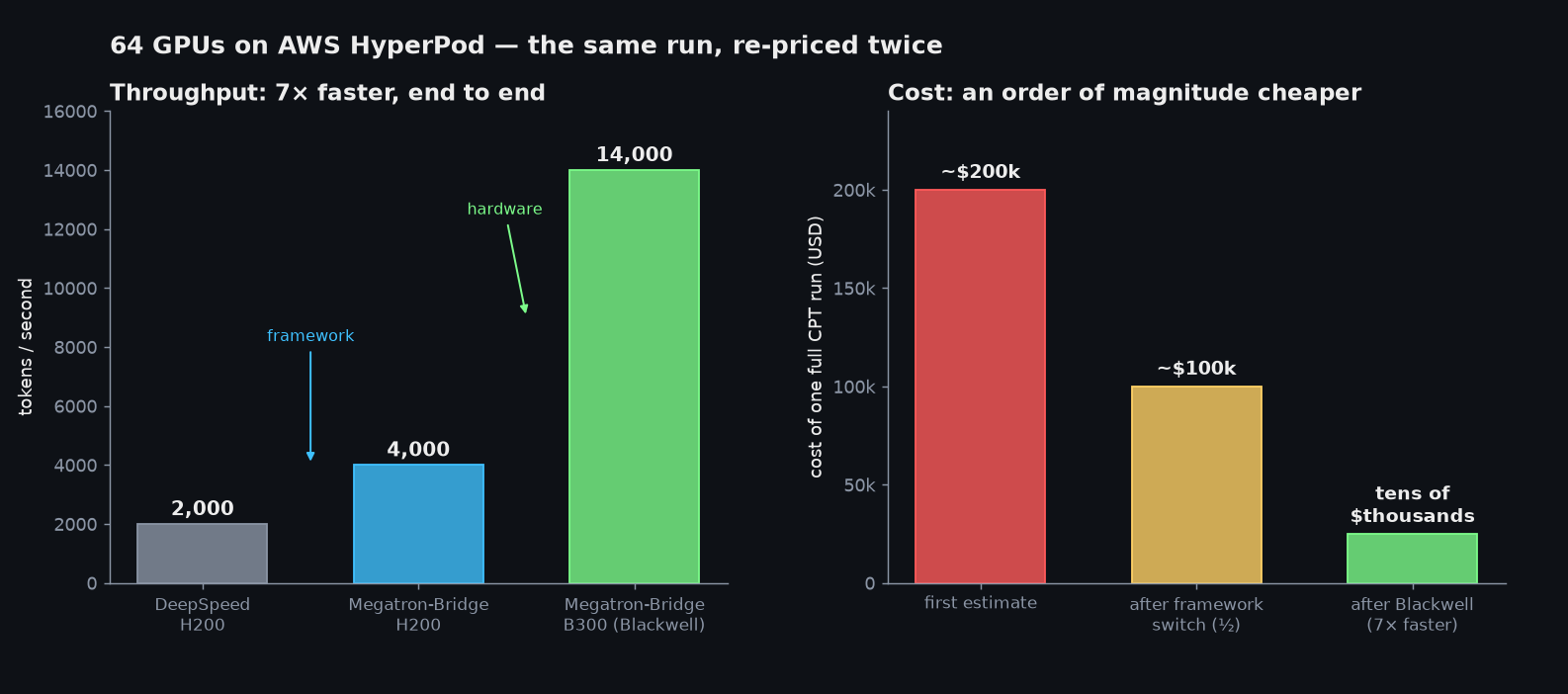
Two changes re-priced the whole project. Switching the training framework from DeepSpeed to Megatron-Bridge roughly halved the cost. Then Blackwell (B300) GPUs arrived mid-project: about 2× the price of an H200 but ~7× the speed, taking throughput from ~2,000 to ~14,000 tokens/second. A full continued-pretrain run that was first estimated at ~$200k ended up costing tens of thousands. (A funny twist: the project was both lavishly and awkwardly resourced — millions of shekels is nothing for training a model, yet the model was small enough that they couldn't just grab the whole cluster for two months. They lived under a tight reservation regime, planning each experiment a week ahead.)
What I took away
Three things stuck with me from this episode. First, the loss is a liar — or at least an unreliable witness. It told them the model was learning through 200 runs that weren't. Second, the leverage is in unglamorous places: a tokenizer's compression ratio, the order of your datasets, a batch-size hyperparameter, a custom packer. Third, and most reassuring: the people doing this admit how much is still trial-and-error. When they were asked what it takes to do this work, the answer wasn't "more GPUs" — it was a research temperament (the team holds advanced degrees in neuroscience and philosophy of mathematics) and a real comfort with infrastructure: Docker, sharding, splitting gradients and optimizers across machines. That's the part nobody puts on the leaderboard, and it's the part that decides whether you ship.
This post is my write-up of the ExplAInable podcast episode on training Hebatron, hosted by Mike Erlihson, with the PwC NEXT team that built the model. Credit to that team (led on the AI side by Israel Weinberger, with the data and evaluation work led by Noam Kaiser, and contributions from teammates including Uri and Shaltiel), to Israel's National AI Program, and to AWS for the HyperPod infrastructure. The model is built on NVIDIA's Nemotron (technical report). The key papers behind the breakthrough are An Empirical Model of Large-Batch Training and Don't Decay the Learning Rate, Increase the Batch Size.
All the figures, the animation, and the interactive explorer above were generated for
this post; the code lives in
research/hebatron/.
The numbers in the charts come from the episode (compression ratios, the 250B-token
budget and batch sizes, throughput and cost); the training-arc animation is a
qualitative schematic of the loss-vs-benchmark pattern, with no values implied.